Formation IX Labs - SEO Technique : crawls, logs et data
Introduction :
SEO technique - points de vue différents sur le SEO technique entre les SEO
Vision classique - 3 piliers ⇒ pyramide 3 piliers / technique = premier pilier
SEO TECHNIQUE
On-page
- code html
- intégration
- éléments bloquants
Structure (focus premier jour) :
- arbo
- maillage interne
- temps de réponse
- gestion des erreurs
"Philosophie" : se mettre à la place des robots
Perte de temps pour le robot si url avec erreur, code source complexe, page lente ⇒ il faut faire gagner du temps à GGbot
https://motherfuckingwebsite.com/
1 - Dashboard SEO
"On n'améliore que ce que l'on mesure"
Objectifs du dashboard :
- centraliser en un endroit KPI importants
- archiver pour avoir un historique
- comparer leur évolution / trouver des corrélations
- détecter rapidement les problèmes
Parfois il faut plusieurs dashboard selon le public (management, équipe dév, données seo, etc)
Le but n'est pas de tout stocker et archiver.
5 minute rule :
- choix des KPI rapide, synthétique
- visualisation des données
Pas d'action précipité : ce n'est pas parce que ton tool dit que le traf baisse qu'il faut fix quoi que ce soit.
Tools :
- Google Analytics : ne pas regarder que le traf SEO, regarder le traf total et les autres canaux d'acquis - peut permettre de remonter des soucis/voir pb de tracking
2 - Isoler le trafic SEO par type de page ou par catégorie
Exemple : /blog/, /predictions/, /promocodes.
- Cela permet de mieux identifier les effets des optimisations.
- Isoler les variations de trafic et identifier les problèmes plus rapidement.
3 - Trafic par device
Sur GA ⇒
- audience mobile
- segments personnalisés
Google discover - opportunité de traf supplémentaire - pas natif dans analytics - peut-être suivi pour voir les pics de traffic
Détection d'anomalies :
- segments par défaut
- segments personnalisés
- vérifier la présence du tag de tracking
- Pollution des données ⇒ si user refuse le bandeau cookies
- spam de refferer ⇒ traf à exclure (taux de rebond élevé/temps de visite élevé ou faible)
Exemple de segments
Visites SEO desktop / mobile / tablette / home / conversion
Visibilité
Vision globale : évolution / tendances
Calculer distance sur la serp en termes de pixels : myposeo / monitorank / aussi dispo dans dataforseo
Rapport de couverture
Autres indicateurs intéressants : fréquence/vitesse de crawl
Monitoring (oseox, oncrawl...)
Pages dans la structure
Nb pages crawlées
Indexable canonical pages
Non index pages
Non canonical pages
→ permet d'automatiser le recettage suite MEP (voir rapidement les potentiels pb)
Liens entrants / temps de chargement
Visibilité des concurrents
On peut automatiser ce monitoring via outils : Excel, gg sheets, data studio, tableau, qlik, homemage + a tester SEO tools for excel / supermetrics for excel, GDS, GG Sheets
Pour la visualisation, plusieurs bibliothèqes js : d3js.org
Alerting pour Analytics (alertes personnalisées)
Possible si baisse de traf de x%
Alertes google https://www.google.fr/alerts possible de mettre site:domain . com inurl:preprod
Résumé :
- Réunir les données
- visualiser les variations
- mettre en place alertes
Crawler : logiciel pr parcourir une page une/analyser le contenu/extraire éléments
Différents besoins de crawl :
1- Crawl complet ⇒
- empreinte à un instant t
- compliqué sur gros volumes
2- Crawl partiel ⇒
- par niveau/répertoire
- plus rapide, moins couteux, plus représentation
3- Scrap ⇒
- 1 ou plusieurs sites
- récup d'info spécifiques
- outils particuliers
Rendering javascript :
Deux phases d'indexation :
- crawl html classique
- puis second crawl avec rendering js si page jugée pertinente
Dans SF : menu config > spider > onglet rendering > enable
Plugin chrome view rendered source : https://chrome.google.com/webstore/detail/view-rendered-source/ejgngohbdedoabanmclafpkoogegdpob
Outils ppaux >
Screaming Frog (le plus connu et simple)
- - : limité en volume/plate/prend la bande passante
Autres :
- + : robuste, fonctionnalités riches, interfaces
Botify (fonctionnalités les plus avancées)
Oncrawl (fonctionnalités les plus avancées)
Deepcrawl
Kelogs
Seolyzer
Crowl.tech : https://www.crowl.tech/#features (tool Julien deneuville)
Config du crawl :
- limite de nb de pages
- limite de profondeur
- crawl des sous domaines ?
- privilégier un user agent gg mobile - puis crawl desktop et voir diff
- attention à la taille du viewport (écran simulé)
Pour ne pas recommencer :
- config extraction de données
- vérifier la présence d'une protection anti crawl (par ex. si cloudflare)
Quand crawl fini :
- comparer pages indexées (sc > couverture) - site: - et nb pages dans le crawl
- pages actives
Erreurs ?
Liens pétés :
- pb technique ?
- erreur manuelle ?
Redirection internes :
- 301 = 500ms
Erreurs serveur :
- pb ponctuel ?
- pb template défaillant ?
Codes réponse :
- 1xx : info
- 2xx : succés
- 3xx : redir
- 4** erreur client
- 5xx : erreur serveur
Si full 200 ⇒ peut être suspect, vérif une page qui n'existe pas et voir le code
Pages bien indexables ?
- robots txt
- meta robots
- entête x robots
Contenu dupliqué ?
- chercher dans titres/urls (trier)/nb mots/poids pages/analyse contenu
Canonical = rustine (dernier recours) - pas sûr que gg choisisse la même url que nous à mettre en avant - logique de faire gagner du temps = nope
Qualité du contenu : à tester avec YTG/1.fr
Maillage interne
Pages importantes ⇒ le moins profondes possibles
Objectifs :
- réduire profondeur
- mettre en avant pages stratégiques
- offrir nav thématisée
Moyens :
- fil d'ariane
- menu
- blocs de liens
Pagerank/surfeur aléatoire
Surfeur aléatoire : visite une page, clique au hasard sur un lien de la page, parfois choisit de ne pas cliquer. Pagerank = probabilité que le surfeur arrive sur une page.
⇒ "surmailler" les pages stratégiques
⇒ liens dans le contenu ont un poids plus important
⇒ le pagerank interne est corrélé avec : le nombre de visites ggbot/traf seo généré
Le site est il rapide ?
Indicateur essentiel :
- crawl budget
- ux/conversion
Les données dépendent de l'outil utilisé/connexion
Outil de référence : webpagetest.org
Protip : catégorisation/segmentation des pages
- par type de page/template
- catégorie/théma
- intérêt business
Croiser les données :
- analytics
- sc
- rankings
SF > config > API Access
https://www.databulle.com/blog/code/crawl-analysis-in-python.html
Pagerank : peut se calculer avec / sans les liens NF et en prenant en compte / ou pas les liens doublons.
Comparer pagerank vs sessions des pages
Pour content pruning = on peut prendre jusqu'à 1 an de data pour les pages inactives (parfois sites à saisonnalité)
Pagination : sert à rendre accessible le catalogue
Python : intérêt traitement de données/générer visu / croiser données
Crawl smarter : crawler souvent, après chaque mep, de temps en temps. Ne pas tjs tout crawler/selon site 4 ou 5 niveau de depth suffit. Conserver les données
15-10 : canalyse de logs / crawl vs logs / maillage interne
- logs serveurs : enregistrement de toutes les requêtes reçues par le serveur web
[inclure ppt]
Logs intéressants pour :
- pour les sites à gros volume
- même pour les autres sites
Possible d'add des infos supp dans les logs : temps de réponse / port utilisé / adresse ip du serveur
Pb possibles sur logs IIS :
- url réécrite (pas par défaut sur iis)
A comparer :
- crawl de gg : logs vs search console
- visites : logs vs analytics
Nouveau rapport dans la seach console
>on peut y voir quels types de fichiers sont crawlés
Pour filtrer le traf des visiteurs :
- lignes qui contiennent "https://.google.fr" (referrer) - a adapter en fonction des tlds
On peut identifier des pb de tracking
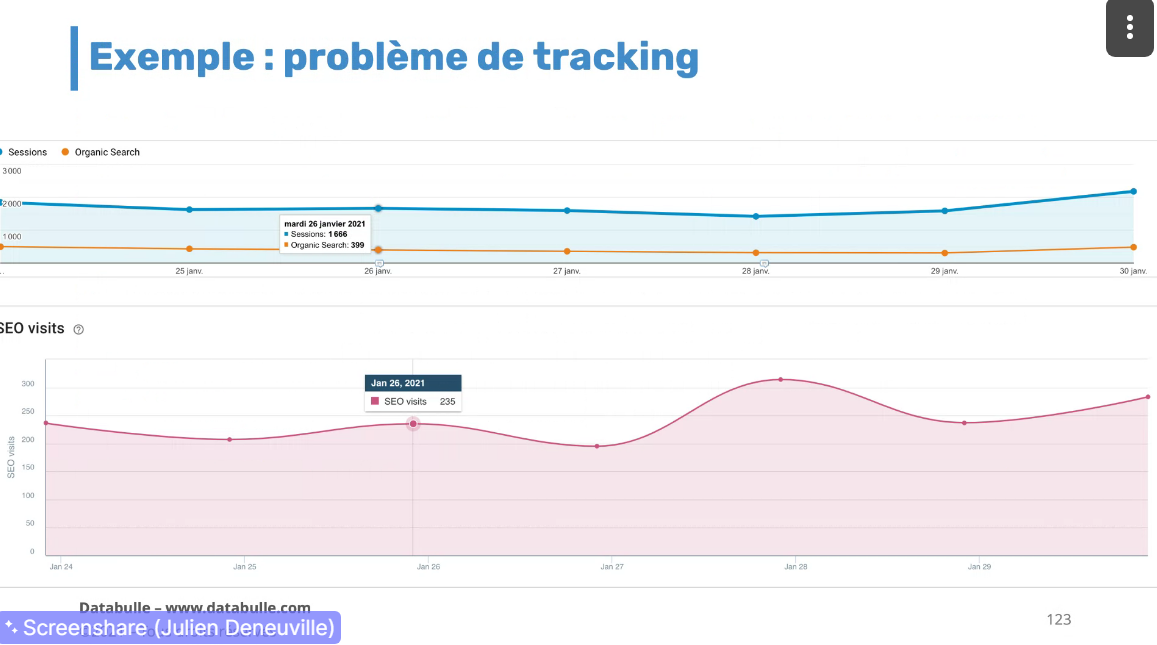
Filtrer données terminal - visualiser dans excel
A analyser :
- codes réponses
500 : pb de code
503 : serveur tient la charge? Code maintenance, dis à gg que temporaire
4xx :
- liens internes cassés
- liens externes cassés (trouver avec majestic/ahrefs) peut aussi etre la source
Comparer :
- urls distinctes logs
- urls crawls
- pages actives analytics
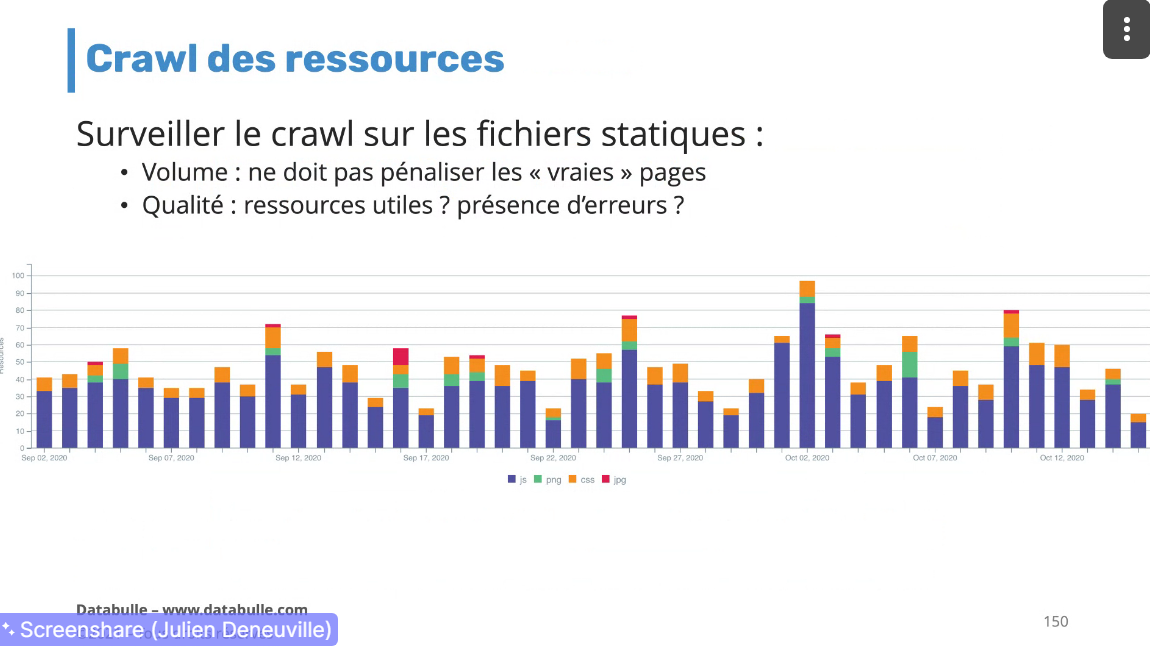
Si bcp plus d'urls logs, possible crawl des ressources (css js...)
- 410 pour que gg prenne en compte rapidement la page suppr
Si pas assez :
- mauvais maillage, pagination accessible ?
Pb d'indexation :
- revoir qualité page ? thin content ? taille de l'inventaire ? popularité du site ?
Page pas indexée, visitée par gg ⇒ pb de qualité de contenu
304 ⇒ bien pour les ressources statiques
sur les pages ⇒ être sûr qu'elles ont pas changé
si on renvoie une 304 et page modifiée là il y a un pb
Maillage interne à improve pour avoir plus de crawl des pages importantes
Codes réponse par heure permet de relever des soucis, pic d'erreur par exemple
Crawl par catégorie, permet de mettre en avant certaines choses :
- certains jours bcp de crawl sur certaines parties
Crawl par profondeur
Maillage interne (objectifs) :
- pas de page orpheline
- gg crawl + les pages importantes
Pas de recette miralce : ce qui fonctionne sur un site ne fonctionnera peut etre pas sur un autre site
Pagination
Maillage transverse : intéressant (exemple amazon - ux + seo)