XPath SEO
https://www.screamingfrog.co.uk/web-scraping/#headings
https://builtvisible.com/seo-guide-to-xpath/
A utiliser dans Screaming Frog AVANT de lancer le crawl :
Sauf indication contraire, extraire sous forme de “Extract Text”
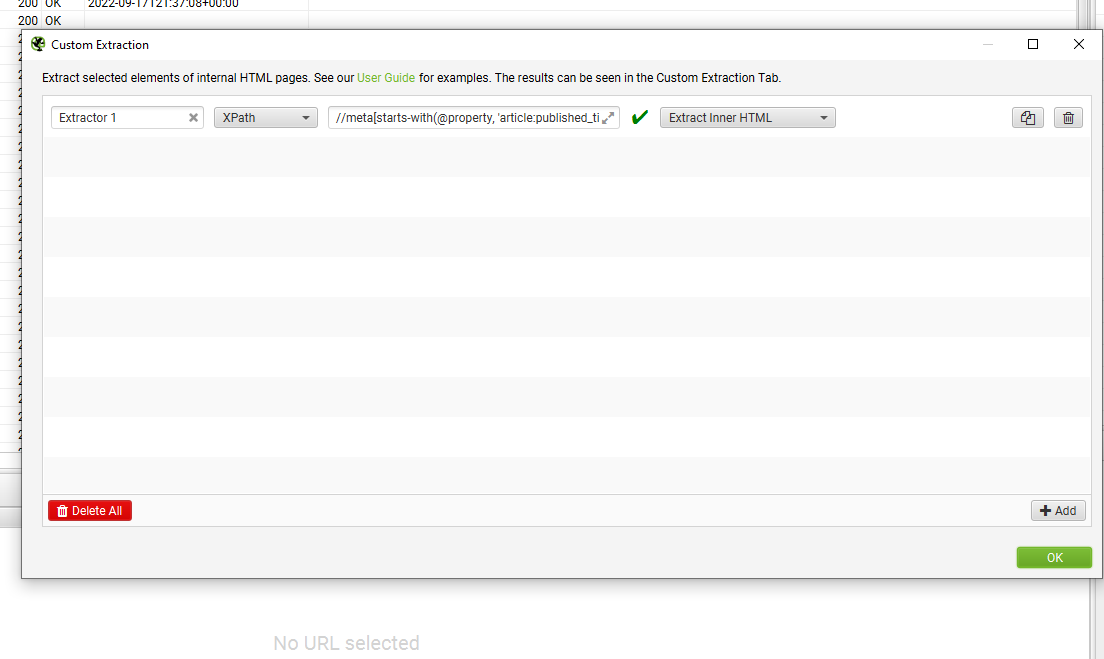
- Date de publication d'un article Wordpress : //meta[starts-with(@property, 'article:published_time')]/@content
- Date last modified d'un article Wordpress : //meta[starts-with(@property, 'og:updated_time')]/@content
- Fil d’Ariane Rank Math (intitulé) : //nav[starts-with(@class, 'rank-math-breadcrumb')]//a[2]
- Fil d’Ariane Rank Math (lien / mettre en “Extract HTML Element”) : //nav[starts-with(@class, 'rank-math-breadcrumb')]//a[2]/@href
- Version AMP de la page //link[@rel='amphtml']/@href
En cas d'utilisation des données structurées événement :
- Pour récupérer le championnat : //div[@class='card-table-title']
- Pour récupérer les équipes : //div[@class='team']
Sinon : clic droit dans l’outil d’inspection sur l’élément qu’on souhaite extraire :